Course Objective 1
Describe probability as a foundation of statistical modeling, including inference and maximum likelihood estimation
From Activity 6 - Logistic Regression
#load library
library(tidyverse)
library(tidymodels)#read in data from URL
resume <- read_csv("https://www.openintro.org/data/csv/resume.csv")#coerce variable of interest to binary
resume$received_callback <- factor(resume$received_callback)# probability of getting a callback
prob_yes = 392/4870
prob_yes[1] 0.08049281odds_yes = (prob_yes/ (1-prob_yes))
odds_yes[1] 0.08753908resume_mod <- logistic_reg() %>%
set_engine("glm") %>%
fit(received_callback ~ race, data = resume, family = "binomial")
tidy(resume_mod) %>%
knitr::kable(digits = 3)| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | -2.675 | 0.083 | -32.417 | 0 |
| racewhite | 0.438 | 0.107 | 4.083 | 0 |
#log odds of perceived black person getting callback
log_odds_callback = -2.68
odds_callback = exp(log_odds_callback)
odds_callback[1] 0.06856315Discussion & Reflection
The logistic regression assignment was a good way to learn about probability, odds, and the roll they play while building models. In this assignment, we analyzed at a data set that looked at the influence of race and gender on the probability of a person receiving a callback after a job interview solely based on their name. We saw that, despite many of the candidates having very good credentials (i.e. a high number of years of experience), that there were a very low number of callbacks given to anyone. When we further looked at black individuals, we saw that the callback probability decreased even more.
I thought that this data set was enlightening in a few ways. One, that you may disproportionately not be given a job opportunity solely based on your name and its perception of race or gender to another person. That level of discrimination, while illegal, does still occur as revealed by this study. As a female, that knowledge is disheartening. I can’t even image what a person of color might experience. I think it’s important to acknowledge your own biases and actively work to avoid them. This data set, in a roundabout way, helped me to think about that in a more present sense.
Course Objective 2
Determine and apply the appropriate generalized linear model for a specific data context
From Mini Competition 2
#convert week data by month #easier for interpretation
data_month <- raw_data %>% mutate(Month = case_when(week <= 4 ~ 'July',
week > 4 & week <= 8 ~ 'August',
week > 8 & week <= 12 ~ 'September',
week > 12 & week <= 16 ~ 'October',
week > 16 & week <= 20 ~ 'November',
week > 20 & week <= 24 ~ 'December',
week > 24 & week <= 28 ~ 'January',
week > 28 & week <= 32 ~ 'February',
week > 32 & week <= 37 ~ 'March',
week > 37 & week <= 41 ~ 'April',
week > 41 & week <= 45 ~ 'May',
week > 45 & week <= 50 ~ 'June',
week > 50 & week <= 53 ~ 'July2',))
data_month$Month <- factor(data_month$Month, levels = c("July", "August", "September",
"October", "November", "December",
"January", "February", "March",
"April", "May", "June", "July2"))
data_month$item_no <- factor(data_month$item_no)#add binary info
data_month_bi <- data_month %>% mutate(sold_binary = case_when(sold > 0 ~ '1',
TRUE ~ '0' ))
data_month_bi$sold_binary <- as.numeric(data_month_bi$sold_binary)data_wider <- data_month %>% pivot_wider(names_from = item_no,
values_from = sold)
data_wider# A tibble: 54 × 490
week Month `020-307` `020-502` `025-207` `02FR182024` `04002032`
<dbl> <fct> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0 July 0 0 0 0 0
2 1 July 80 0 100 0 0
3 2 July 0 0 0 0 0
4 3 July 0 0 0 0 284
5 4 July 0 84 0 0 88
6 5 August 0 0 0 0 440
7 6 August 0 0 0 0 60
8 7 August 0 84 0 0 75
9 8 August 80 0 100 0 0
10 9 Septem… 0 0 0 0 0
# ℹ 44 more rows
# ℹ 483 more variables: `04120002` <dbl>, `0822203` <dbl>,
# `10055.011010` <dbl>, `10055.011020` <dbl>, `10055.011212` <dbl>,
# `10055.011220` <dbl>, `10055.011224` <dbl>, `10055.011420` <dbl>,
# `10055.011425` <dbl>, `10055.011616` <dbl>, `10055.011620` <dbl>,
# `10055.011624` <dbl>, `10055.011625` <dbl>, `10055.011820` <dbl>,
# `10055.012020` <dbl>, `10055.012025` <dbl>, …#see overall trends across time
ggplot(data = data_month, aes(x = Month,
y = sold,
color = item_no,
fill = item_no)) +
geom_col() +
theme_bw() +
theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
legend.position = "none")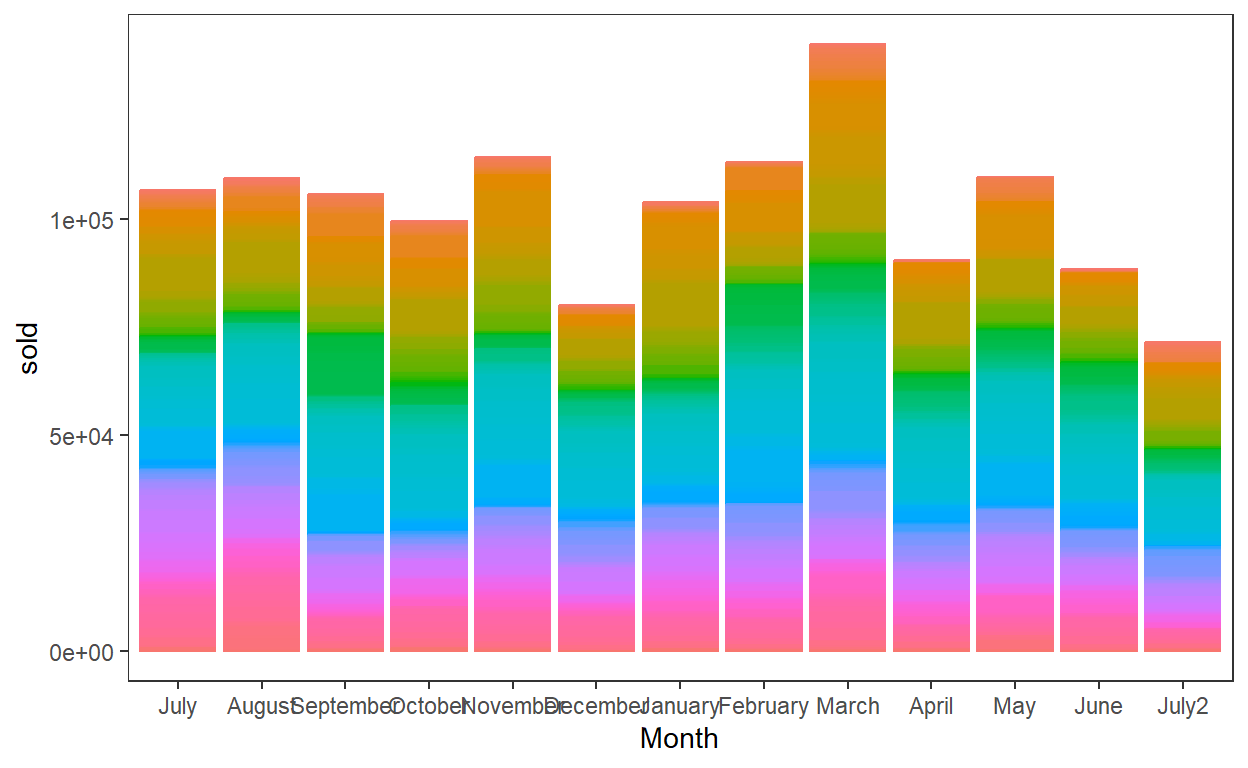
summary(data_month_bi) item_no week sold
020-307 : 54 Min. : 0.0 Min. : 0.00
020-502 : 54 1st Qu.:13.0 1st Qu.: 0.00
025-207 : 54 Median :26.5 Median : 0.00
02FR182024: 54 Mean :26.5 Mean : 50.62
04002032 : 54 3rd Qu.:40.0 3rd Qu.: 2.00
04120002 : 54 Max. :53.0 Max. :7200.00
(Other) :26028
Month sold_binary
July : 2440 Min. :0.0000
March : 2440 1st Qu.:0.0000
June : 2440 Median :0.0000
August : 1952 Mean :0.2516
September: 1952 3rd Qu.:1.0000
October : 1952 Max. :1.0000
(Other) :13176 #install.packages("caTools")
library(caTools)
set.seed(123)
split_data <- sample.split(data_month_bi$sold, SplitRatio = 0.7)
test_data <- subset(data_month_bi, split_data == FALSE)
train_data <- subset(data_month_bi, split_data == TRUE)set.seed(123)
split_data2 <- sample.split(data_month$sold, SplitRatio = 0.7)
test_data2 <- subset(data_month, split_data2 == FALSE)
train_data2 <- subset(data_month, split_data2 == TRUE)
fit2 <- glm(sold ~ Month + item_no, data = train_data2)# A tibble: 500 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -1.43 0.425 -3.35 0.000796
2 MonthAugust 0.135 0.0986 1.37 0.170
3 MonthSeptember -0.121 0.101 -1.20 0.232
4 MonthOctober -0.0883 0.101 -0.875 0.382
5 MonthNovember 0.132 0.0986 1.34 0.180
6 MonthDecember -0.317 0.104 -3.03 0.00244
7 MonthJanuary 0.122 0.0989 1.23 0.217
8 MonthFebruary 0.0330 0.0986 0.335 0.738
9 MonthMarch 0.151 0.0929 1.63 0.103
10 MonthApril -0.124 0.101 -1.22 0.222
# ℹ 490 more rows# A tibble: 114 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -1.43 0.425 -3.35 0.000796
2 MonthDecember -0.317 0.104 -3.03 0.00244
3 MonthJune -0.284 0.0971 -2.93 0.00339
4 item_no02FR182024 -2.20 1.10 -2.01 0.0449
5 item_no10055.011010 2.07 0.536 3.86 0.000113
6 item_no10055.011620 2.48 0.560 4.43 0.00000957
7 item_no10055.011625 1.54 0.518 2.98 0.00288
8 item_no10055.012020 1.69 0.545 3.10 0.00193
9 item_no10055.012025 1.71 0.526 3.24 0.00118
10 item_no10055.021625 1.43 0.535 2.67 0.00765
# ℹ 104 more rowsaccuracy <- mean(head(test_data$pred$`ifelse(prob > 0.75, "1", "0")`, 35)
== head(test_data$sold_binary, 35))
accuracy #77% accuracy[1] 0.7714286#what is our second model predicting at?
accuracy2 #2% accuracy[1] 0.02857143Our first model is predicting with 77% accuracy
Discussion & Reflection
Mini competition 2 set the goal to create a model to complete the task of projecting a company’s sales of widgets and then communicate our findings to a general audience. In this example, we utilized a generalized linear model approach to accomplish this task and framed the output in terms of months of projected high sales. This way, the company was able to use our predictions to choose which widgets should be kept in excess stock during specific months. One of the main goals of this assignment was to intentionally frame the output and predictions in a manner that is easily digestible to people who are not formally trained in statistics. A challenge of this goal was to strike a balance between effective communication without condescension- this is often a critique which non-academics have with academia.
One problem with our approach to the generalized linear model was with our training and testing models. While we randomized the dataset and split our data into a 70:30 training and testing sets, this ignores the collinearity of the data. For example, it is possible that one widget over multiple months could have been selected for either the training or testing sets. To ensure an even separation of widgets, a better approach would have been to select by unique widget and then subset the data. This project stretched my thinking about a problem, not only in what approach to use, but also how to effectively communicate the findings to a general audience
Course Objective 3
Conduct model selection for a set of candidate models
From Mini Competition 1
challenge_data <- readr::read_csv("2019_data.csv")selected_vars <- c("FSSPORTX", "FSVOL", "FSMTNG", "FSPTMTNG", "FSFUNDRS",
"FSCOMMTE", "FSCOUNSLR", "FSFREQ","FSATCNFN", "FHCHECKX",
"FHHELP", "FHPLACE", "SCCHOICE", "SPUBCHOIX", "SEGRADES",
"SCONSIDR")#create a new data set
new_data <- challenge_data[, selected_vars]## Splitting data into train and test and fitting the model
# set seed before random split
set.seed(40)
# put 80% of the data into the training set
data_split <- initial_split(filtered_data4, prop = 0.80)
# assign the two splits to data frames - with descriptive names
data_train <- training(data_split)
data_test <- testing(data_split)
# splits
data_train# A tibble: 7,407 × 16
FSSPORTX FSVOL FSMTNG FSPTMTNG FSFUNDRS FSCOMMTE FSCOUNSLR FSFREQ
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <dbl>
1 Yes No Yes Yes Yes No No 20
2 Yes Yes Yes Yes Yes Yes Yes 8
3 Yes No Yes No Yes No Yes 5
4 Yes Yes Yes Yes Yes No Yes 10
5 Yes No Yes Yes Yes No Yes 3
6 Yes Yes Yes Yes Yes Yes Yes 10
7 Yes No Yes Yes Yes No No 1
8 No No No No No No No 2
9 No No No Yes No No No 1
10 Yes Yes Yes Yes Yes Yes No 14
# ℹ 7,397 more rows
# ℹ 8 more variables: FSATCNFN <chr>, FHCHECKX <chr>, FHHELP <chr>,
# FHPLACE <chr>, SCCHOICE <chr>, SPUBCHOIX <chr>, SEGRADES <dbl>,
# SCONSIDR <chr>Fitting the model
#fit the mlr model
lm_spec <- linear_reg() %>%
set_mode("regression") %>%
set_engine("lm")
initial_model <- lm_spec %>%
fit(SEGRADES ~ FSSPORTX+FSVOL+FSMTNG+FSPTMTNG+FSATCNFN+FSFUNDRS+FSCOMMTE+
FSCOUNSLR+FSFREQ+SCCHOICE+SPUBCHOIX+FHCHECKX+FHHELP+FHPLACE+
FSMTNG*FHHELP+FSPTMTNG*FHHELP+SCONSIDR, data = data_train)
stats<- tidy(initial_model)final_model1 <- lm_spec %>%
fit(SEGRADES ~ FSSPORTX+FSATCNFN+FHCHECKX+FHHELP+FSMTNG*FHHELP+FSMTNG+
FSCOMMTE+SCCHOICE+FHPLACE, data = data_train)
tidy(final_model1)# A tibble: 10 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 1.81 0.0776 23.3 1.15e-115
2 FSSPORTXYes -0.170 0.0415 -4.09 4.44e- 5
3 FSATCNFNYes 0.410 0.0365 11.2 4.40e- 29
4 FHCHECKXmany 0.425 0.0480 8.84 1.16e- 18
5 FHHELPmany 0.0912 0.102 0.895 3.71e- 1
6 FSMTNGYes -0.261 0.0569 -4.58 4.66e- 6
7 FSCOMMTEYes -0.178 0.0429 -4.14 3.55e- 5
8 SCCHOICEYes -0.0986 0.0308 -3.20 1.38e- 3
9 FHPLACEYes -0.207 0.0441 -4.69 2.76e- 6
10 FHHELPmany:FSMTNGYes 0.232 0.107 2.18 2.96e- 2#final model chosen after the backward selection using AIC values
final_model2 <- lm_spec %>%
fit(SEGRADES ~ FSSPORTX+FSATCNFN+FHCHECKX+FHHELP+FSMTNG*FHHELP+FSMTNG+
FSCOMMTE+SCCHOICE+FHPLACE+FSFUNDRS, data = data_train)
tidy(final_model2)# A tibble: 11 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 1.81 0.0776 23.3 6.23e-116
2 FSSPORTXYes -0.153 0.0425 -3.60 3.19e- 4
3 FSATCNFNYes 0.415 0.0366 11.4 1.25e- 29
4 FHCHECKXmany 0.424 0.0480 8.84 1.19e- 18
5 FHHELPmany 0.0941 0.102 0.924 3.56e- 1
6 FSMTNGYes -0.248 0.0574 -4.32 1.60e- 5
7 FSCOMMTEYes -0.162 0.0438 -3.69 2.24e- 4
8 SCCHOICEYes -0.0963 0.0308 -3.13 1.78e- 3
9 FHPLACEYes -0.204 0.0441 -4.64 3.62e- 6
10 FSFUNDRSYes -0.0608 0.0331 -1.84 6.59e- 2
11 FHHELPmany:FSMTNGYes 0.231 0.107 2.17 3.00e- 2## Making predictions and check for accuracy of predictions
predictions <- predict(final_model1, new_data = data_test)#check accuracy of the predictions
true_labels <- data_test$SEGRADES
predictions_round <- round(predictions)# rounding to get whole numbers instea of decimals
accuracy1 <- sum(predictions_round == true_labels) / length(true_labels)
accuracy1[1] 0.3439525final_model2
predictions2 <- predict(final_model2, new_data = data_test)true_labels <- data_test$SEGRADES
predictions2_round <- round(predictions2)
accuracy2 <- sum(predictions2_round == true_labels) / length(true_labels)
accuracy2[1] 0.3363931Discussion & Reflection
The goal of the first mini competition was to try and assess which factors contribute to a students’ academic success. We were given a very large data set and a big challenge was to pare down which factors to even use in the model. We used a backward selection model to help with this process and had several iterations of our model run. We then compared the accuracy of a few of the final models and chose the model with the highest accuracy (which was still only 34%).
One challenge with this assignment was the code itself. Since I was the one presenting, I needed to go over and make sure that the code was correctly written and the models ran as expected. One thing I learned to appreciate was how each person tackles a given problem differently than how I would initially approach it, and we are all different when it comes to code organization. Reading another person’s code and needing to make changes to it when necessary really helped my own debugging skills and shed light on the necessity for comments. Overall, it was a fun but challenging assignment.
Course Objective 4
Communicate the results of statistical models to a general audience
From Mini Competition 2 - see code above
knitr::include_graphics("images/comp2_graph.jpg")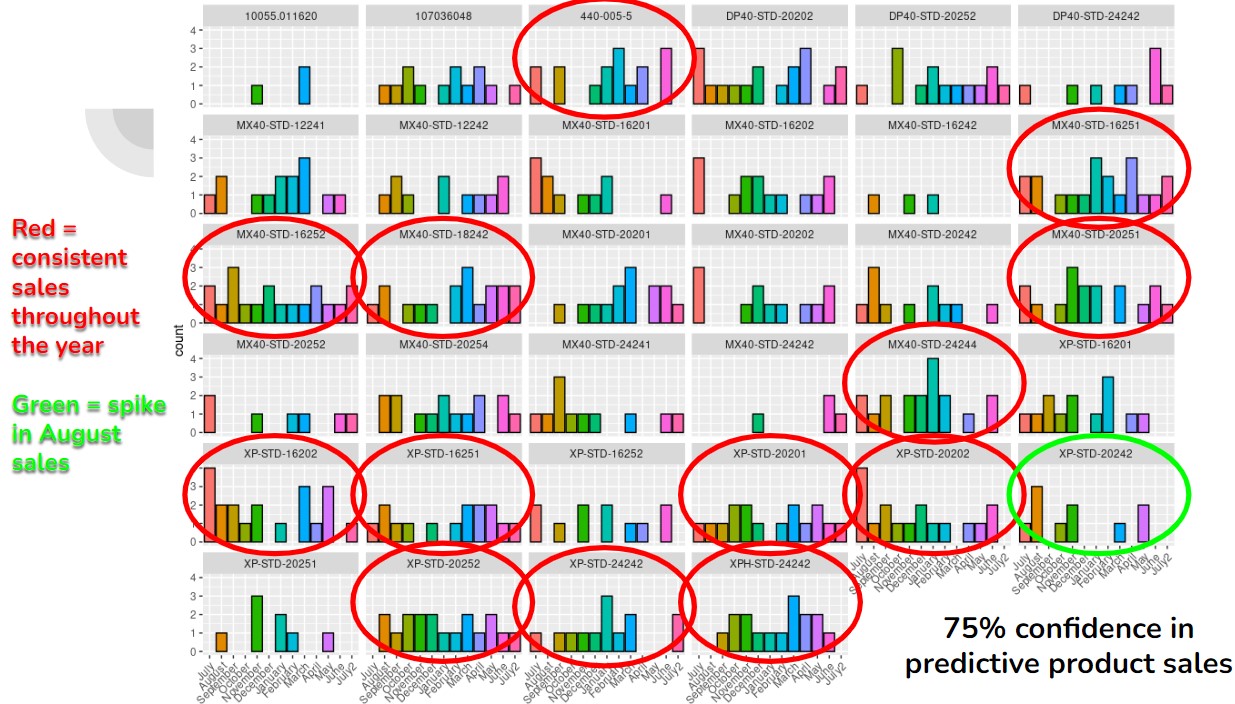
Figure 1: Graph illustrating predictions in sales
knitr::include_graphics("images/comp2.jpg")
Figure 2: Communicating findings to our audience
Discussion & Reflection
As mentioned above, a main goal of this project was to use a model to predict sales of products, then communicate those predictions to a general audience. While I was not the one to give the presentation, I did play a major role in the development of the models as well as creating the presentation. It was difficult to find a balance between effectively and accurately communicating what was done, why it was done, and how it was done in a manner that makes sense to non-statisticians. This is something that I know I struggle with, as I tend to drone and give too many unimportant details when storytelling. Working on this assignment in a group helped me to see the level of effective communication that can occur, even with complicated topics.
Additionally, seeing other groups present their information and how they approached the assignment was equally insightful. One group in particular, I recall had the most visually impactful presentation and looked incredibly professional. I felt that they did a great job communicating their work in an effective way, without diminishing their own efforts or demeaning their audience.
Course Objective 5
Use programming software (i.e., R) to fit and assess statistical models
See above for examples of R code
Discussion & Reflection
Between the multiple assignments and mini competitions in this class, we used R for all analyses. I am constantly amazed at the growth in this language that I continue to develop during my studies. The books, videos, and lectures all taught me new skills in R and these are tools which I will take with me as my career progresses. The amount of effort in this course to succeed was self-driven. In my opinion, these topics are of the sort that one will continue to learn new ways to approach them, so the code that I write today will be very different from the code I write in the future. Additionally, working on the mini competitions with other people helped me see how other people attack a problem in R, starting with how the clean the data, organize their code, and make final interpretations. Reading other people’s code helped me to realize how I struggle with comments in my own code and how I need to improve on that aspect.
Overall, this class was a lot to keep up with between readings, videos, and assignments, but I believe that I have the tools to continue my learning journey from here. I particularly enjoyed many of the in-class discussions with my peers - we all come from such different backgrounds in studies and life that it was insightful to hear different perspectives on various topics such as AI, data feminism, or career aspirations. Sometimes it’s easy to feel alone on your own journey, so I think finding common ground among your peers is important and brings a sense of community into your life.